In this post, I will explain some of the tools, which help Hadoop Administrators in bench marking and finding the bottlenecks in a hadoop cluster.
The Hadoop comes with a number of benchmarks, which are bundled in hadoop-*test*.jar and hadoop-*examples*.jar. The four tools that we will discuss in detail are TestDFSIO, nmbench, mrbench (in hadoop-*test*.jar) and TeraGen / TeraSort / TeraValidate (in hadoop-*examples*.jar).
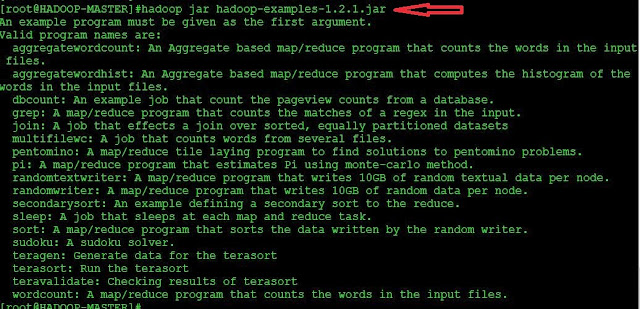
The options available in "hadoop-*examples*.jar" and "hadoop-*test*.jar" is the snapshot below:

TOOL 1: TestDFSIO: I/O PERFOMANCE
The TestDFSIO tool is used to test the I/O performance of HDFS.It is useful in finding the bottlenecks in network, hardware, OS and cluster machines particularly the NameNode and the DataNodes.
When a write test is run with option -write, the TestDFSIO writes files to /benchmarks/TestDFSIO on HDFS. Benchmark results are saved in a local file called TestDFSIO_results.log in the current local directory. To use a different filename, set the -resFile parameter appropriately (e.g. -resFile result.txt).

The above command will produce 500 MB data, with 512 MB block size.
TeraSort:
TeraSort: Run the actual TeraSort benchmark
The syntax is as follows:
----------
hadoop jar hadoop-*examples*.jar terasort <input dir> <output dir>
----------
For example:
-------
hadoop jar hadoop-*examples*.jar terasort /data/input /data/output
------
In the above example, the input dir is "/data/input" and output directory is "/data/output" in HDFS.
TeraValidate: Validate the output data of terasort.
The syntax for TeraValidate:
-----
hadoop jar hadoop-*examples*.jar teravalidate <terasort output dir (= input data)> <teravalidate output dir>
-----
Example:
--------
hadoop jar hadoop-*examples*.jar teravalidate /data/output /data/teravalidate-output
--------
If everything is properly sorted then, teravalidate will not produce any output in "/data/teravalidate-output".
From the command line, we can get the details of the completed job as below:
Syntax:
--------
hadoop job -history all <job output directory>
--------
Example:
--------
hadoop job -history all /data/output/
--------
Parameter 3: mrbench ( MapReduce Benchmark).
MRBench the source code is src/test/org/apache/hadoop/mapred/MRBench.java. It loops a small job a number of times. It is a very complimentary benchmark to the "large-scale" TeraSort benchmark because MRBench checks whether small job runs are responsive and running efficiently on a cluster. Its focus is on the MapReduce layer as its impact on the HDFS layer is very limited.
The available options of "mrbench" can be interpreted as below:



The Hadoop comes with a number of benchmarks, which are bundled in hadoop-*test*.jar and hadoop-*examples*.jar. The four tools that we will discuss in detail are TestDFSIO, nmbench, mrbench (in hadoop-*test*.jar) and TeraGen / TeraSort / TeraValidate (in hadoop-*examples*.jar).
The options available in "hadoop-*examples*.jar" and "hadoop-*test*.jar" is the snapshot below:


The TestDFSIO tool is used to test the I/O performance of HDFS.It is useful in finding the bottlenecks in network, hardware, OS and cluster machines particularly the NameNode and the DataNodes.
When a write test is run with option -write, the TestDFSIO writes files to /benchmarks/TestDFSIO on HDFS. Benchmark results are saved in a local file called TestDFSIO_results.log in the current local directory. To use a different filename, set the -resFile parameter appropriately (e.g. -resFile result.txt).
The source code for this is laocated at:"$HADOOP_HOME/src/test/org/apache/hadoop/fs/TestDFSIO.java"
The command to run a write test that generates 5 output files of size 1GB and in total 5 GB is:
------
hadoop jar hadoop-*test*.jar TestDFSIO -write -nrFiles 5 -fileSize 1000
-------
A special note, to know duration from your current terminal itself take help of unix command "time". So, the command will be:
-------
time hadoop jar hadoop-*test*.jar TestDFSIO -write -nrFiles 5 -fileSize 1000
--------
To perform a read test, using 5 input files of size 1GB is:
-------
hadoop jar hadoop-*test*.jar TestDFSIO -read -nrFiles 5 -fileSize 1000
-------
To clean up and remove test data use "-clean" switch:
-------
hadoop jar hadoop-*test*.jar TestDFSIO -clean
-------
This will remove the directory "/benchmarks/TestDFSIO".
Understating the result:

From the above result the important parameters to note are "Throughput" and "Average IO rate".
NOTE: Replication factor of the cluster plays an important role in managing these values. For example, a cluster having an replication factor of "2" will have better throughput and I/O as compared to a cluster with replication factor of "3".
Suppose, you want to test this by changing the default replication factor of "3". take the help of "hdfs-site.xml".
Parameter 2: TeraGen/TeraSort/TeraValidate:
It is a benchmark that combines testing the HDFS and MapReduce layers of an Hadoop cluster.
We can use the TeraSort benchmark on our Hadoop configuration if the cluster passed a TestDFSIO benchmark. TeraSort is helpful to determine whether map and reduce slot assignments are sound (as they depend on the variables such as the number of cores per TaskTracker node and the available RAM), whether other MapReduce-related parameters such as io.sort.mb and mapred.child.java.opts are set to proper values.
TeraGen: It generates a random output data. The syntax is as follows:
------
hadoop jar hadoop-*examples*.jar teragen <number of 100-byte rows> <output dir>
-----
Example:
--------
hadoop jar hadoop-*examples*.jar teragen 5242880 /data/input
--------
The above command will produce "500 MB' file to directory "/data/input".
The actual TeraGen data format per row is:
-------------
<10 bytes key><10 bytes rowid><78 bytes filler>\r\n
-------------
1) The keys are random characters from the set ' '..'~'.
2) The rowid is the right justified row id as a int.
3) The filler consists of 7 runs of 10 characters from ‘A’ to ‘Z’.
Suppose, the Blocksize is set to 128MB, then teragen will get complete in a short span of time.
Sometimes, you may have to do testing my increasing the blocksize to 512MB, then it can be done via command line itself:
-----------
hadoop jar hadoop-*examples*.jar teragen -D dfs.block.size=536870912 5242880 /data/input
------------
The above command will produce 500 MB data, with 512 MB block size.
TeraSort:
TeraSort: Run the actual TeraSort benchmark
The syntax is as follows:
----------
hadoop jar hadoop-*examples*.jar terasort <input dir> <output dir>
----------
For example:
-------
hadoop jar hadoop-*examples*.jar terasort /data/input /data/output
------
In the above example, the input dir is "/data/input" and output directory is "/data/output" in HDFS.
TeraValidate: Validate the output data of terasort.
The syntax for TeraValidate:
-----
hadoop jar hadoop-*examples*.jar teravalidate <terasort output dir (= input data)> <teravalidate output dir>
-----
Example:
--------
hadoop jar hadoop-*examples*.jar teravalidate /data/output /data/teravalidate-output
--------
If everything is properly sorted then, teravalidate will not produce any output in "/data/teravalidate-output".
From the command line, we can get the details of the completed job as below:
Syntax:
--------
hadoop job -history all <job output directory>
--------
Example:
--------
hadoop job -history all /data/output/
--------
Parameter 3: mrbench ( MapReduce Benchmark).
MRBench the source code is src/test/org/apache/hadoop/mapred/MRBench.java. It loops a small job a number of times. It is a very complimentary benchmark to the "large-scale" TeraSort benchmark because MRBench checks whether small job runs are responsive and running efficiently on a cluster. Its focus is on the MapReduce layer as its impact on the HDFS layer is very limited.
The available options of "mrbench" can be interpreted as below:

The command to run a loop of small 3 test job is:
---------
hadoop jar hadoop-*test*.jar mrbench -numRuns 3
---------
The output of the above command is as below:

This means that, the average time to complete the job is 21 seconds.
Parameter 4: nnbench for NameNode benchmark.
This is useful for load testing of NameNode hardware and configuration. It generates a lot of HDFS-related requests for the sole purpose of putting a high stress on the NameNode. The benchmark can simulate requests for creating, reading, renaming and deleting files on HDFS.
The available options for the tool are,

Command:
--------
hadoop jar hadoop-*test*.jar nnbench -operation create_write -maps 12 -reduces 6 -blockSize 1 -bytesToWrite 0 -numberOfFiles 1000 -replicationFactorPerFile 3 -readFileAfterOpen true -baseDir /benchmarks/NNBench-`hostname -s`
---------
The above command will run a NameNode benchmark that creates 1000 files using 12 maps and 6 reducers. It uses a custom output directory based on the machine’s short hostname. This is a simple trick to ensure that one box does not accidentally write into the same output directory of another box running NNBench at the same time.
Reference links:
-------
-------
I will explain about the utilization of these tools, in my next post.
No comments:
Post a Comment
Note: only a member of this blog may post a comment.