In this post, I will explain about the process of setting up a single node Hadoop cluster.

PLEASE NOTE THE IP ADDRESS OF THE MACHINE IN WHICH WE ARE INSTALLING HADOOP IS 192.168.150.210.
Before installing Hadoop, we need to make sure that prerequisite are met.
Prerequisite 1: Check whether java is installed as below

If java is not installed follow the post below, to install the same:
-------
--------
Prerequisite 2 : Now, we need to setup key based SSH authentication.
To setup ssh key authentication follow the link below:
--------
---------
Now, "ssh localhost" command should work as below:
Now, if it is not set properly then it will be asking for password.
Let us start hadoop installation if prerequisites are met.
Step 1: Download desired hadoop package from the link below:
-----
http://apache.claz.org/hadoop/common/
----
cd /usr/local/
wget http://apache.claz.org/hadoop/common/hadoop-1.2.1/hadoop-1.2.1-bin.tar.gz
----
Now, rename the extracted folder as below:
----
mv hadoop-1.2.1 hadoop
-----
Once done, edit ~/.bashrc and enter the below variables:
-----
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin
-----
Then run the below command to make it effective.
-----
exec bash
-----
Step 2:
------
Now, we need to set environment variables in the following file:
vi /usr/local/hadoop/conf/hadoop-env.sh
Edit the below variable with java path installed.
------
export JAVA_HOME=/opt/jdk1.7.0_75/
------
Step 3:
------
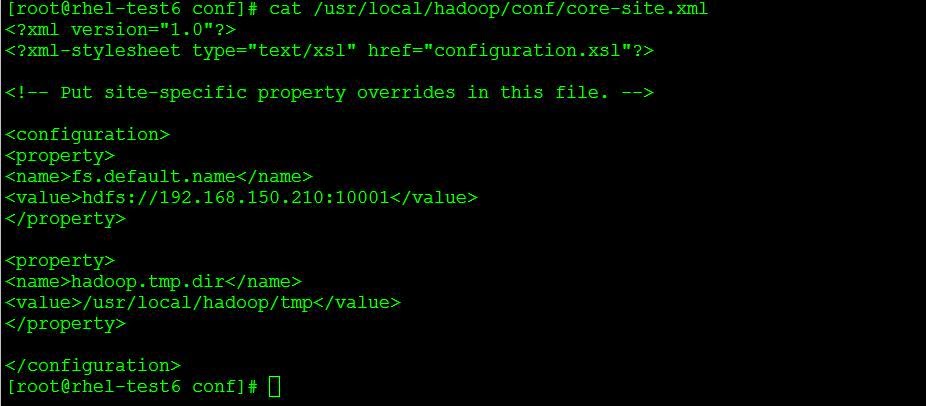
vi /usr/local/hadoop/conf/core-site.xml
Enter the below parameters inside "configuration" that is already present:
---------
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.150.210:10001</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
--------------
Step 4:
---------
vi /usr/local/hadoop/conf/mapred-site.xml
----------
Enter the below entries :
----------
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.150.210:10002</value>
</property>
</configuration>

---------------
Step 5:
--------
Now, run the below command to format hadoop name node:
---------------
hadoop namenode -format
---------------
The output looks as below:

Step 6: Now, run the below command to start the services:
------
start-all.sh
-------
The output will looks as below:

Now, if you run command "jps", you will be able to see all services running on a single node.

Step 4:
---------
vi /usr/local/hadoop/conf/mapred-site.xml
----------
Enter the below entries :
----------
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.150.210:10002</value>
</property>
</configuration>
-----------
The files will be looking as below:
Step 5:
--------
Now, run the below command to format hadoop name node:
---------------
hadoop namenode -format
---------------
The output looks as below:
Step 6: Now, run the below command to start the services:
------
start-all.sh
-------
The output will looks as below:
Now, if you run command "jps", you will be able to see all services running on a single node.
Now, to see the details of namenode using the below URLs:
-------
http://192.168.150.210:50070/ ---> Details of name node.
http://192.168.150.210:50030/ ----> Details of Mapreduce tasks.
------
I will be writing a detailed post on multinode hadoop cluster next.
Keep watching :)
No comments:
Post a Comment
Note: only a member of this blog may post a comment.